Prueba t de Student
En estadística, una prueba t de Student, prueba t-Student, o Test-T es cualquier prueba en la que el estadístico utilizado tiene una distribución t de Student si la hipótesis nula es cierta. Se aplica cuando la población estudiada sigue unadistribución normal pero el tamaño muestral es demasiado pequeño como para que el estadístico en el que está basada la inferencia esté normalmente distribuido, utilizándose una estimación de la desviación típica en lugar del valor real. Es utilizado en análisis discriminante.

Historia
El estadístico t fue introducido por William Sealy Gosset en 1908, un químico que trabajaba para la cervecería Guinness de Dublín. Student era su seudónimo de escritor.1 2 3 Gosset había sido contratado gracias a la política de Claude Guiness de reclutar a los mejores graduados de Oxford y Cambridge, y con el objetivo de aplicar los nuevos avances en bioquímica y estadística al proceso industrial de Guiness.2 Gosset desarrolló el test t como una forma sencilla de monitorizar la calidad de la famosa cerveza stout. Publicó su test en la revista inglesa Biometrika en el año 1908, pero fue forzado a utilizar un seudónimo por su empleador, para mantener en secreto los procesos industriales que se estaban utilizando en la producción. Aunque de hecho, la identidad de Gosset era conocida por varios de sus compañeros estadísticos.4
Usos
Entre los usos más frecuentes de las pruebas t se encuentran:
- El test de locación de muestra única por el cual se comprueba si la media de una población distribuida normalmente tiene un valor especificado en una hipótesis nula.
- El test de locación para dos muestras, por el cual se comprueba si las medias de dos poblaciones distribuidas en forma normal son iguales. Todos estos test son usualmente llamados test t de Student, a pesar de que estrictamente hablando, tal nombre sólo debería ser utilizado si las varianzas de las dos poblaciones estudiadas pueden ser asumidas como iguales; la forma de los ensayos que se utilizan cuando esta asunción se deja de lado suelen ser llamados a veces comoPrueba t de Welch. Estas pruebas suelen ser comúnmente nombradas como pruebas t desapareadas o de muestras independientes, debido a que tienen su aplicación mas típica cuando las unidades estadísticas que definen a ambas muestras que están siendo comparadas no se superponen.5
- El test de hipótesis nula por el cual se demuestra que la diferencia entre dos respuestas medidas en las mismas unidades estadísticas es cero. Por ejemplo, supóngase que se mide el tamaño del tumor de un paciente con cáncer. Si el tratamiento resulta efectivo, lo esperable seria que el tumor de muchos pacientes disminuyera de tamaño luego de seguir el tratamiento. Esto con frecuencia es referido como prueba t de mediciones apareadas o repetidas.5 6
- El test para comprobar si la pendiente de una regresión lineal difiere estadísticamente de cero.
Formula
La mayor parte de las pruebas estadísticas t tienen la forma  , donde Z y s son funciones de los datos estudiados. Típicamente, Z se diseña de forma tal que resulte sensible a la hipótesis alternativa (p.ej. que su magnitud tienda a ser mayor cuando la hipótesis alternativa es verdadera), mientras que s es un parámetro de escala que permite que la distribución de T pueda ser determinada.
, donde Z y s son funciones de los datos estudiados. Típicamente, Z se diseña de forma tal que resulte sensible a la hipótesis alternativa (p.ej. que su magnitud tienda a ser mayor cuando la hipótesis alternativa es verdadera), mientras que s es un parámetro de escala que permite que la distribución de T pueda ser determinada.
, donde Z y s son funciones de los datos estudiados. Típicamente, Z se diseña de forma tal que resulte sensible a la hipótesis alternativa (p.ej. que su magnitud tienda a ser mayor cuando la hipótesis alternativa es verdadera), mientras que s es un parámetro de escala que permite que la distribución de T pueda ser determinada.
Por ejemplo, en una prueba t de muestra única,  , donde
, donde 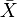 es la media muestral de los datos, n es el tamaño muestral, y σ es la desviación estándar de la población de datos; s en una prueba de muestra única es
es la media muestral de los datos, n es el tamaño muestral, y σ es la desviación estándar de la población de datos; s en una prueba de muestra única es 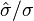 , donde
, donde  es la desviación estándar muestral.
es la desviación estándar muestral.
, donde es la media muestral de los datos, n es el tamaño muestral, y σ es la desviación estándar de la población de datos; s en una prueba de muestra única es , donde es la desviación estándar muestral.
Las asunciones subyacentes en una prueba t son:
- Que Z sigue una distribución normal bajo la hipótesis nula.
- ps2 sigue una distribución χ2 con p grados de libertad bajo la hipótesis nula, y donde p es una constante positiva.
- Z y s son estadísticamente independientes.
En una prueba t específica, estas condiciones son consecuencias de la población que está siendo estudiada, y de la forma en que los datos han sido muestreados. Por ejemplo, en la prueba t de comparación de medias de dos muestras independientes, deberíamos realizar las siguientes asunciones:
- Cada una de las dos poblaciones que están siendo comparadas sigue una distribución normal. Esto puede ser demostrado utilizando una prueba de normalidad, tales como una prueba Shapiro-Wilk o Kolmogórov-Smirnov, o puede ser determinado gráficamente por medio de un gráfico de cuantiles normales Q-Q plot.
- Si se está utilizando la definición original de Student sobre su prueba t, las dos poblaciones a ser comparadas deben poseer las mismas varianzas, (esto se puede comprobar utilizando una prueba F de igualdad de varianzas, una prueba de Levene, una prueba de Bartlett, o una prueba de Brown-Forsythe, o estimarla gráficamente por medio de un gráfico Q-Q plot). Si los tamaños muestrales de los dos grupos comparados son iguales, la prueba original de Student es altamente resistente a la presencia de varianzas desiguales.7 la Prueba de Welch es insensible a la igualdad de las varianzas, independientemente de si los tamaños de muestra son similares.
- Los datos usados para llevar a cabo la prueba deben ser muestreados independientemente para cada una de las dos poblaciones que se comparan. Esto en general no es posible determinarlo a partir de los datos, pero si se conoce que los datos han sido muestreados de manera dependiente (por ejemplo si fueron muestreados por grupos), entonces la prueba t clásica que aquí se analiza, puede conducir a resultados erróneos.
Pruebas t para dos muestras apareadas y desapareadas
Las pruebas-t de dos muestras para probar la diferencia en las medias pueden ser desapareadas o en parejas. Las pruebas t pareadas son una forma de bloqueo estadístico, y poseen un mayor poder estadístico que las pruebas no apareadas cuando las unidades apareadas son similares con respecto a los "factores de ruido" que son independientes de la pertenencia a los dos grupos que se comparan [cita requerida]. En un contexto diferente, las pruebas-t apareadas pueden utilizarse para reducir los efectos de los factores de confusión en un estudio observacional.
Desapareada
Las pruebas t desapareadas o de muestras independientes, se utilizan cuando se obtienen dos grupos de muestras aleatorias, independientes e idénticamente distribuidas a partir de las dos poblaciones a ser comparadas. Por ejemplo, supóngase que estamos evaluando el efecto de un tratamiento médico, y reclutamos a 100 sujetos para el estudio. Luego elegimos aleatoriamente 50 sujetos para el grupo en tratamiento y 50 sujetos para el grupo de control. En este caso, obtenemos dos muestras independientes y podríamos utilizar la forma desapareada de la prueba t. La elección aleatoria no es esencial en este caso, si contactamos a 100 personas por teléfono y obtenemos la edad y género de cada una, y luego se utiliza una prueba t bimuestral para ver en que forma la media de edades difiere por género, esto también sería una prueba t de muestras independientes, a pesar de que los datos son observacionales.
Apareada
Las pruebas t de muestras dependientes o apareadas, consisten típicamente en una muestra de pares de valores con similares unidades estadísticas, o un grupo de unidades que han sido evaluadas en dos ocasiones diferentes (una prueba t de mediciones repetitivas). Un ejemplo típico de prueba t para mediciones repetitivas sería por ejemplo que los sujetos sean evaluados antes y después de un tratamiento.
Una prueba 't basada en la coincidencia de pares muestrales se obtiene de una muestra desapareada que luego es utilizada para formar una muestra apareada, utilizando para ello variables adicionales que fueron medidas conjuntamente con la variable de interés.8
La valoración de la coincidencia se lleva a cabo mediante la identificación de pares de valores que consisten en una observación de cada una de las dos muestras, donde las observaciones del par son similares en términos de otras variables medidas. Este enfoque se utiliza a menudo en los estudios observacionales para reducir o eliminar los efectos de los factores de confusión.
Cálculos
Las expresiones explícitas que pueden ser utilizadas para obtener varias pruebas t se dan a continuación. En cada caso, se muestra la fórmula para una prueba estadística que o bien siga exactamente o aproxime a una distribución t de Student bajo la hipótesis nula. Además, se dan los apropiados grados de libertad en cada caso. Cada una de estas estadísticas se pueden utilizar para llevar a cabo ya sea un prueba de una cola o prueba de dos colas.
Una vez que se ha determinado un valor t, es posible encontrar un valor P asociado utilizando para ello una tabla de valores de distribución t de Student. Si el valor P calulado es menor al límite elegido por significancia estadística (usualmente a niveles de significancia 0,10; 0,05 o 0,01), entonces la hipótesis nula se rechaza en favor de la hipótesis alternativa.
Prueba t para muestra única
En esta prueba se evalúa la hipótesis nula de que la media de la población estudiada es igual a un valor especificado μ0, se hace uso del estadístico:

donde 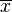 es la media muestral, s es la desviación estándar muestral y n es el tamaño de la muestra. Los grados de libertad utilizados en esta prueba se corresponden al valor n − 1.
es la media muestral, s es la desviación estándar muestral y n es el tamaño de la muestra. Los grados de libertad utilizados en esta prueba se corresponden al valor n − 1.
es la media muestral, s es la desviación estándar muestral y n es el tamaño de la muestra. Los grados de libertad utilizados en esta prueba se corresponden al valor n − 1.Pendiente de una regresión lineal
Supóngase que se está ajustando el modelo:

donde xi, i = 1, ..., n son conocidos, α y β son desconocidos, y εi es el error aleatorio en los residuales que se encuentra normalmente distribuido, con un valor esperado 0 y una varianza desconocida σ2, e Yi, i = 1, ..., n son las observaciones.
Se desea probar la hipótesis nula de que la pendiente β es igual a algún valor especificado β0 (a menudo toma el valor 0, en cuyo caso la hipótesis es que x e y no están relacionados).
sea

Luego

tiene una distribución t con n − 2 grados de libertad si la hipótesis nula es verdadera. El error estándar de la pendiente:

puede ser reescrito en términos de los residuales:

Luego
 se encuentra dado por:
se encuentra dado por: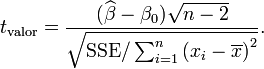
Prueba t para dos muestras independientes
Iguales tamaños muestrales, iguales varianzas
Esta prueba se utiliza solamente cuando:
- los dos tamaños muestrales (esto es, el número, n, de participantes en cada grupo) son iguales;
- se puede asumir que las dos distribuciones poseen la misma varianza.
Las violaciones a estos presupuestos se discuten más abajo.
El estadístico t a probar si las medias son diferentes se puede calcular como sigue:
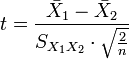
Donde

Aquí 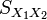 es la desviación estándar combinada, 1 = grupo uno, 2 = grupo 2. El denominador de t es el error estándar de la diferencia entre las dos medias.
es la desviación estándar combinada, 1 = grupo uno, 2 = grupo 2. El denominador de t es el error estándar de la diferencia entre las dos medias.
es la desviación estándar combinada, 1 = grupo uno, 2 = grupo 2. El denominador de t es el error estándar de la diferencia entre las dos medias.
Por prueba de significancia, los grados de libertad de esta prueba se obtienen como 2n − 2 donde n es el número de participantes en cada grupo.
Diferentes tamaños muestrales, iguales varianzas
Esta prueba se puede utilizar únicamente si se puede asumir que las dos distribuciones poseen la misma varianza. (Cuando este presupuesto se viola, mirar más abajo). El estadístico t si las medias son diferentes puede ser calculado como sigue:
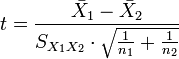
Donde

Nótese que las fórmulas de arriba, son generalizaciones del caso que se da cuando ambas muestras poseen igual tamaño (sustituyendo n por n1 y n2).
es un estimador de la desviación estándar común de ambas muestras: esto se define así para que su cuadrado sea un estimador sin sesgo de la varianza común sea o no la media iguales. En esta fórmula, n = número de participantes, 1 = grupo uno, 2 = grupo dos. n − 1 es el número de grados de libertad para cada grupo, y el tamaño muestral total menos dos (esto es, n1 + n2 − 2) es el número de grados de libertad utilizados para la prueba de significancia.Diferentes tamaños muestrales, diferentes varianzas
Esta prueba es también conocida como prueba t de Welch y es utilizada únicamente cuando se puede asumir que las dos varianzas poblacionales son diferentes (los tamaños muestrales pueden o no ser iguales) y por lo tanto deben ser estimadas por separado. El estadístico t a probar cuando las medias poblacionales son distintas puede ser calculado como sigue:

donde
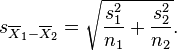
Aquí s2 es el estimador sin sesgo de la varianza de las dos muestras, n = número de participantes, 1 = grupo uno, 2 = grupo dos. Nótese que en este caso,
 no es la varianza combinada. Para su utilización en pruebas de significancia, la distribución de este estadístico es aproximadamente igual a una distribución t ordinaria con los grados de libertad calculados según:
no es la varianza combinada. Para su utilización en pruebas de significancia, la distribución de este estadístico es aproximadamente igual a una distribución t ordinaria con los grados de libertad calculados según:
Esta ecuación es llamada la ecuación Welch–Satterthwaite. Nótese que la verdadera distribución de este estadístico de hecho depende (ligeramente) de dos varianzas desconocidas.
Prueba t dependiente para muestras apareadas
Esta prueba se utiliza cuando las muestras son dependientes; esto es, cuando se trata de una única muestra que ha sido evaluada dos veces (muestras repetidas) o cuando las dos muestras han sido emparejadas o apareadas. Este es un ejemplo de un test de diferencia apareada.

Para esta ecuación, la diferencia entre todos los pares tiene que ser calculada. Los pares se han formado ya sea con resultados de una persona antes y después de la evaluación o entre pares de personas emparejadas en grupos de significancia (por ejemplo, tomados de la misma familia o grupo de edad: véase la tabla). La media (XD) y la desviación estándar (sD) de tales diferencias se han utilizado en la ecuación. La constante μ0 es diferente de cero si se desea probar si la media de las diferencias es significativamente diferente de μ0. Los grados de libertad utilizados son n − 1.
| Ejemplo de pares emparejados | |||
| Par | Nombre | Edad | Test |
|---|---|---|---|
| 1 | Juan | 35 | 250 |
| 1 | Joana | 36 | 340 |
| 2 | Jaimito | 22 | 460 |
| 2 | Jesica | 21 | 200 |
| Ejemplo de muestras repetidas | |||
| Número | Nombre | Test 1 | Test 2 |
|---|---|---|---|
| 1 | Miguel | 35% | 67% |
| 2 | Melanie | 50% | 46% |
| 3 | Melisa | 90% | 86% |
| 4 | Michell | 78% | 91% |
Ejemplos desarrollados
Sea A1 denotando un grupo obtenido tomando 6 muestras aleatorias a partir de un grupo mayor:
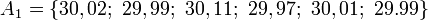
y sea A2 denotando un segundo grupo obtenido de manera similar:

Estos podrían ser, por ejemplo, los pesos de tornillos elegidos de un montón.
Vamos a llevar a cabo la prueba de hipótesis contando como hipótesis nula de que la media de las poblaciones de las cuales hemos tomado las muestras son iguales.
La diferencia entre las dos medias de muestras, cada uno denotado por  , la cual aparece en el numerador en todos los enfoques de dos muestras discutidas anteriormente, es
, la cual aparece en el numerador en todos los enfoques de dos muestras discutidas anteriormente, es
, la cual aparece en el numerador en todos los enfoques de dos muestras discutidas anteriormente, es
La desviaciones estándar muestrales para las dos muestras son aproximadamente 0,05 y 0,11 respectivamente. Para muestras tan pequeñas, una prueba de igualdad entre las varianzas de las dos poblaciones no es muy poderoso. Pero ya que los tamaños muestrales son iguales, las dos formas de las dos pruebas t se pueden desarrollar en forma similar en este ejemplo.
Varianzas desiguales
Si se decide continuar con el enfoque para varianzas desiguales (discutido anteriormente), los resultados son
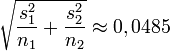
y

El resultado de la prueba estadística es aproximadamente 1,959. El valor P para la prueba de dos colas da un valor aproximado de 0,091 y el valor P para la prueba de una cola es aproximadamente 0,045.
Varianzas iguales
Si se sigue el enfoque para varianzas iguales (discutido anteriormente), los resultados son
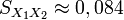
y

Ya que el tamaño de las muestras es igual (ambas tienen 6 elementos), el resultado de la prueba estadística es nuevamente un valor que se aproxima a 1.959. Debido a que los grados de libertad son diferentes de la prueba para varianzas desiguales, los valores P difieren ligeramente de los obtenidos un poco más arriba. Aquí el valor P para la prueba de dos colas es aproximadamente 0,078, y el valor P para una cola es aproximadamente 0,039. Así, si hubiera una buena razón para creer que las varianzas poblacionales son iguales, los resultados serían algo más sugerentes de una diferencia en los pesos medios de las dos poblaciones de tornillos.
Alternativas a la prueba t para problemas de locación
La prueba t provee un mecanismo exacto para evaluar la igualdad entre las medias de dos poblaciones que tengan varianzas iguales, aunque el valor exacto de las mismas sea desconocido. El test de Welch es una prueba aproximadamente exacta para el caso en que los datos poseen una distribución normal, pero las varianzas son diferentes. Para muestras moderadamente grandes y pruebas de una cola, el estadístico t es moderadamente robusto a las violaciones de la asunción de normalidad.9
Para ser exactos tanto las pruebas t como las z requiere que las medias de las muestras sigan una distribución normal, y la prueba t adicionalmente requiere que la varianza de las muestras siga una distribución Chi-cuadrado (χ2), y que la media muestral y la varianza muestral sean estadísticamente independientes. La normalidad de los valores individuales de los datos no es un requisito para que estas condiciones se cumplan. Por el teorema del límite central, las medias muestrales de muestras moderadamente grandes también aproximan una distribución normal, incluso si los datos individuales no están normalmente distribuidos. Para datos no normales, la distribución de la varianza muestral puede desviarse sustancialmente de una distribución χ2. Sin embargo, si el tamaño muestral es grande, el teorema de Slutsky indica que la distribución de las varianzas muestrales ejerce un efecto muy pequeño en la distribución de la prueba estadística. Si los datos son substancialmente no normales, y el tamaño muestral es pequeño, la prueba t puede entregar resultados equivocados.
Cuando la asunción de normalidad no se sostiene, una alternativa no paramétrica a la prueba t puede ofrecer un mejor poder estadístico. Por ejemplo, para dos muestras independientes cuando la distribución de datos es asimétrica (esto es, que la distribución está sesgada) o la distribución tiene colas muy grandes, entonces el test de suma de posiciones (ranks) de Wilcoxon (conocido también como prueba U de Mann-Whitney) puede tener de tres a cuatro veces mayor poder estadístico que una prueba t.9 10 11
La contraparte no paramétrica a la prueba t de muestras apareadas es la prueba Wilcoxon de suma de posiciones con signo para muestras pareadas. Para una discusión sobre cuando hacer una elección entre las alternativas t y no paramétricos, consulte a Sawilowsky.12
El análisis de varianza "one-way" generaliza la prueba t de dos muestras para casos donde los datos pertenecen a más que dos grupos.
Pruebas multivariadas
Una generalización del estadístico t de Student llamada estadístico t cuadrado de Hotelling, permite la comprobación de hipótesis en múltiples (y a menudo correlacionadas) mediciones de la misma muestra. Por ejemplo, un investigador puede presentar un número de sujetos a un test de múltiples escalas de personalidad (p.ej el de cinco grandes rasgos de personalidad). Debido a que las medidas de este tipo suelen estar muy correlacionadas, no es aconsejable llevar a cabo varias pruebas univariadas, ya que esto supondría descuidar la covarianza entre las medidas e inflar la probabilidad de rechazar falsamente al menos una hipótesis (error de tipo I). En este caso una única prueba múltiple es preferible para llevar a cabo las pruebas de hipótesis. El estadístico t de Hosteling sigue una distribución T 2, sin embargo en la práctica, esta distribución se utiliza muy raramente, y en cambio se suele convertir en una distribución de tipo F.
Prueba T 2 monomuestral
Para una prueba multivariable de unica muestra, la hipótesis es que el vector medio (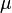 ) es igual a un vector (
) es igual a un vector (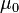 ) dado. La prueba estadística se define como:
) dado. La prueba estadística se define como:
) es igual a un vector () dado. La prueba estadística se define como:
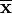 es el vector de columnas medio y
es el vector de columnas medio y 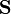 una
una  .
.Prueba T 2 bimuestral
Para un test multivariable de dos muestras, la hipótesis es que los vectores medios ( ,
,  ) de las dos muestras son iguales. La prueba estadística se define como:
) de las dos muestras son iguales. La prueba estadística se define como:
, ) de las dos muestras son iguales. La prueba estadística se define como:
Implementaciones
La mayoría de los programas tipo hoja de cálculo y paquetes estadísticos de lenguajes de programación, tales como QtiPlot, OpenOffice.org Calc, LibreOffice Calc, Microsoft Excel, SAS, SPSS, Stata, DAP, gretl, R, Python ([1]), PSPP, Infostaty Minitab, incluyen implementaciones del test t de Student.
Lecturas adicionales
- Boneau, C. Alan (1960). «The effects of violations of assumptions underlying the t test». Psychological Bulletin 57 (1): pp. 49–64. doi:
- Edgell, Stephen E., & Noon, Sheila M (1984). «Effect of violation of normality on the t test of the correlation coefficient». Psychological Bulletin 95 (3): pp. 576–583. doi:.
Referencias
- ↑ Richard Mankiewicz, The Story of Mathematics (Princeton University Press), p.158.
- ↑ a b O'Connor, John J.; Robertson, Edmund F., «Biografía de Prueba t de Student» (en inglés), MacTutor History of Mathematics archive, Universidad de Saint Andrews.
- ↑ Fisher Box, Joan (1987). «Guinness, Gosset, Fisher, and Small Samples».Statistical Science 2 (1): pp. 45–52. doi:.
- ↑ Raju TN (2005). «William Sealy Gosset and William A. Silverman: two "students" of science». Pediatrics 116 (3): pp. 732–5. doi:. PMID 16140715.
- ↑ a b Fadem, Barbara (2008). High-Yield Behavioral Science (High-Yield Series). Hagerstwon, MD: Lippincott Williams & Wilkins. ISBN 0-7817-8258-9.
- ↑ Zimmerman, Donald W. (1997). «A Note on Interpretation of the Paired-Samples t Test». Journal of Educational and Behavioral Statistics 22 (3): pp. 349–360.
- ↑ Markowski, Carol A; Markowski, Edward P. (1990). «Conditions for the Effectiveness of a Preliminary Test of Variance». The American Statistician 44(4): pp. 322–326. doi:.
- ↑ David, HA; Gunnink, Jason L (1997). «The Paired t Test Under Artificial Pairing». The American Statistician 51 (1): pp. 9–12. doi:.
- ↑ a b Sawilowsky S., Blair R. C. (1992). «A more realistic look at the robustness and type II error properties of the t test to departures from population normality». Psychological Bulletin 111 (2): pp. 353–360. doi:.
- ↑ Blair, R. C.; Higgins, J.J. (1980). «A comparison of the power of Wilcoxon’s rank-sum statistic to that of Student’s t statistic under various nonnormal distributions.». Journal of Educational Statistics 5 (4): pp. 309–334.doi:.
- ↑ Fay, MP; Proschan, MA (2010). «Wilcoxon-Mann-Whitney or t-test? On assumptions for hypothesis tests and multiple interpretations of decision rules». Statistics Surveys 4: pp. 1–39. doi:. PMID20414472. PMC 2857732.
- ↑ Sawilowsky S (2005). «Misconceptions leading to choosing the t test over the Wilcoxon Mann-Whitney U test for shift in location parameter». Journal of Modern Applied Statistical Methods 4 (2): pp. 598–600.
- O'Mahony, Michael (1986). Sensory Evaluation of Food: Statistical Methods and Procedures. CRC Press. pp. 487. ISBN 0-824-77337-3.
- Press, William H.; Saul A. Teukolsky, William T. Vetterling, Brian P. Flannery (1992). Numerical Recipes in C: The Art of Scientific Computing. Cambridge University Press. pp. p. 616. ISBN 0-521-43108-5.
Wikipedia
No hay comentarios:
Publicar un comentario